Statistics data is often published as tabular data by statistics offices and governmental agencies. In last years, many of these institutions have addressed an interoperable way of releasing their data, by means of semantic technologies. Existing approaches normally employ ad-hoc techniques to transform this tabular data to the Statistics Knowledge Graph (SKG) and materialize it. This approach imposes the need of periodical maintenance to ensure the synchronization between the dataset and the transformation result. Using R2RML, the W3C mapping language recommendation, the generation of virtual SKG is possible thanks to the capability of its processors. However, as the size of the R2RML mapping documents depends on the number of columns in the tabular data and the number of dimensions to be generated, it may be prohibitively large, hindering its maintenance. In this paper we propose an approach to reduce the size of the mapping document by extending RMLC, a mapping language for tabular data. We provide a mapping translator from RMLC to R2RML and a comparative analysis over two different real statistics datasets.
Introduction
Statistics data is one of the most common ways of sharing public information nowadays. PDF, HTML and, especially, CSV format, are some of the most used formats of tabular data being published on the web by statistics agencies. Whereas this is still the main trend, many agencies worldwide are embracing semantic technologies for publishing their resources as Statistics Knowledge Graph (SKG), which is the knowledge graph on the web that stores and allows access to statistics linked data. In many cases both formats co-exist, allowing to access the information in different ways.
Due to high volume and variability of data, the transformation from tabular to SKG-oriented formats requires a process that is standard and maintainable. We identify two main approaches for transforming tabular data to Statistics Knowledge Graph (SKG). The first approach is an ad-hoc approach, such as one that has been reported in , in which CSV data is converted into RDF Data Cube using a set of custom rules. The second approach is defined on the basis of mapping languages, such as the RDB2RDF W3C Recommendation, R2RML, in which transformations are codified in an standard language, with several tools available for applying them.
In an ad-hoc approach , a processor which is the main component responsible for the transformation process, is developed for a specific purpose. Those processors are not commonly used for other solutions. The SKG resulting from the transformation process is stored in a triple store and there is a need for repeating the transformation process whenever the original statistics data changes to ensure that generated SKG is synchronised with the original statistics data. On the other hand, using R2RML to generate SKG brings several benefits in comparison to the ad-hoc approach. There are many R2RML processors available which means that one is not restricted to use a particular processor and may easily use another if necessary. Furthermore, many of those processors have incorporated techniques for keeping the desired SKG virtual, thus eliminating the need of synchronization between the tabular data and SKG. A virtualization process is highly recommended when the data published is volatile because it ensures that the retrieved data is updated. This is achieved by translating SPARQL queries posed to the virtual SKG into another query supported by the underlying data source and evaluated on the original dataset .
summarizes our discussion regarding the approaches on transforming statistical data into SKG.
Features
Ad-Hoc
R2RML
Processor Type
Solution Specific
General Purpose
# Processors
1
Many
Materialization
Yes
Yes
Virtualization
No
Yes
Comparison of Approaches for Transforming Statistics Data to SKG
The size of the R2RML mapping documents depends on the number of columns in the tabular data and number of dimensions to be generated. For example, a CSV file that contains data from all the European countries will need an R2RML mapping with one section defined the required dimensions for each country. Considering the correlation between the size of a mapping document and its complexity, i.e., the more lines it has, the more difficult it is to maintain, a crucial task is to reduce the size of the mappings to ease the mapping maintenance task. We address this challenge by proposing an approach to reduce the size of the mapping documents using an iterator that has been incorporated into RMLC, an RDF Mapping Language for heterogeneous CSV files.
The rest of the paper is organized as follows. discusses related work on the generation of knowledge graphs from heterogeneous datasets. In we compare a naive approach of generating SKG using R2RML mappings against our proposed approach using RMLC Iterator. In we report our experiment on generating virtual SKG from two different datasets (tourism and immigration) coming from different agencies. Finally concludes this paper and outlines future work.
Related Work
Several mapping languages have been proposed in the state of the art for the provision of ontology-based access to structured or semi-structured data (e.g. relational databases, XML, JSON, CSV). Ontology Based Data Access (OBDA) approaches can be focused on query translation only (e.g., RDB2RDF approaches) or may also consider query rewriting, where ontology-based reasoning is also taken into account in the rewriting process. There is a variety of algorithms for query rewriting and query translation, which may come with optimizations depending on the characteristics of data sources, mappings and ontologies.
The most relevant mapping language is R2RML , a W3C recommendation focused on describing mappings to transform RDB data into RDF, which is now supported by most OBDA or RDB2RDF systems. Several works have focused on the formalization of the query translation process (from SPARQL to SQL), and on the proposal of performance improvements of the resulting queries. For example, in authors adapt the algorithm defined in with R2RML mappings, including optimisations. This is also similar in the work described in . Both systems allow querying CSV files by importing them into a relational database or by delegating their treatment to a SQL federated tool , respectively. In the statistics field there are also works that use R2RML to generate materialized SKG from tabular files.
Other works have focused on extending or adapting mapping languages with new features or providing access to other data formats. The de-facto standard for transforming data from JSON, XML or CSV to RDF is RML. However, the RML implementation (RML-Mapper) only provides support for materialization, that is, a full transformation of the input dataset into RDF. xR2RML is an RML extension that provides a way to query MongoDB and JSON files.
A lot of work has been made translating CSV files and spreadsheets to RDF, like XLWrap or SML and tools like Tarql, Vertere-RDF or CSV2RDF. Other works provide an user interface to ease the transformation process from tabular data to RDF like QBer or Karma . The uptake of the CSV on the Web W3C Recommendation is also still low.
These approaches are mainly focused on materialization process, which is not suitable when the dataset is dynamic. In any case, for the best of our knowledge, none of those approaches deal with the reduction of the mapping size, so the maintenance problem remains.
From CSV to OBDA
In this section we discuss and exemplify two different approaches for transforming tabular data to SKG, the first one being the baseline which allows to illustrate the advantages of our approach.
Approach 1 - Naive
Given a CSV file containing statistics data, a typical way to transform it to SKG using R2RML mappings is to create one TriplesMap for each column corresponding to a slice of a dimension, for example January in Time dimension or Male in Gender dimension. The TriplesMap will have the following properties:
Its rr:logicalTable property specifies the source CSV file ()
Its Subject Map specifies qb:Observation as the generated triples’ RDF type ()
It will have a pair of PredicateObjectMap mappings that specify a slice of a dimension and its values ()
It will have a PredicateObjectMap mapping that specifies which dataset the generated triples belong to ()
Considering that a typical statistics CSV file contains many columns, the size of the R2RML mapping document grows linearly with the number of columns. The main issue with the first approach is the size of the R2RML/RML mapping, where the mapping expert has to create a TriplesMap for each column to answer the desirable SPARQL queries, as we will show in the Evaluation section.
Approach 2 - RMLC iterator
In this approach, we aim to reduce the size of a R2RML mapping for statistics data by incorporating an iterator variable into RMLC. This mapping language has been equipped with several features to be able to deal with the heterogeneity of tabular data. For example, the exploitation of implicit relations among CSV files, or the creation of an enriched database schema based on the information provided by the mappings and the datasets.
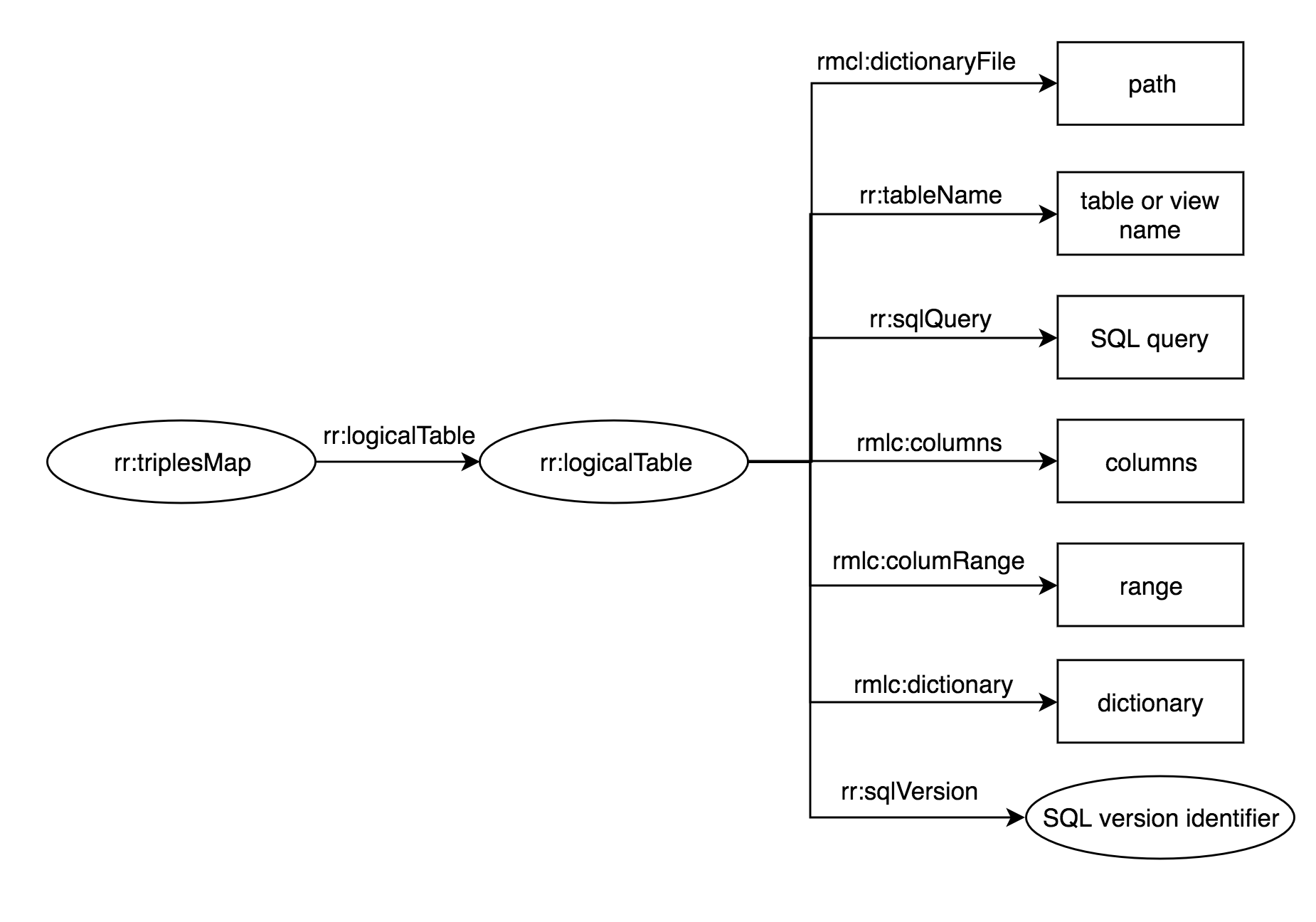
We identify that the only difference between those TriplesMaps is the name of the column, which provides a unique identifier to the TriplesMap object and the access to the data of each column. By incorporating a variable that references the target columns, RMLC-Iterator reduces the size of the mapping while maintaining the semantics of the R2RML mapping. This variable is formalized in the mapping language by incorporating four new properties () to the Logical Table object:
the rmlc:columns whose value must be an array of column names that exist in the CSV file.
the rmlc:columnRange whose value must be an array with cardinality two and the values have to be column names that exist in the CSV file.
the rmlc:dictionaryFile whose value must a path to a JSON file that defines the correlation between the columns and their aliases in JSON format.
the rmlc:dictionary whose value must be a JSON schema that defines a correlation between the columns and their aliases in JSON format.
depicts an example of the usage of the rmlc:columns property, in which the subset of the CSV columns to be used in the transformation process is specified. This property is defined using a LogicalTable object. We use the rmlc:dictionary (or its corresponding rmlc:dictionaryFile) property to establish a correlation between a column and its alias, that is useful in some parts of the mappings. These properties are based on JSON syntax for easing their creation to the mapping editors.
During the mapping translation process, the variables are replaced with the name of each column or its alias, as defined in the LogicalTable object. The resulting R2RML mapping contains as many TriplesMap objects as the number of columns specified in the RMLC properties. In this example, the identifier of each TriplesMap, the URI of the subjects and the object of the sltsv:numberOfArrivals predicates, include the variables so they will be replaced with the name of a column or its alias. The R2RML mapping will contain three TriplesMap objects, one for each defined column. All the iterator variables can be specified anywhere in the mapping, as shown in , using the {$column} or {$alias} syntax.
In order to ensure that RMLC-Iterator aligns with R2RML, we have developed a mapping translator that converts its mapping document with an iterator variable to a R2RML mapping with multiple TriplesMap objects. In this way, we reduce the size of the R2RML mapping document, minimizing the time of the mapping creation and supporting an easier maintenance. Besides, as RMLC is aligned to R2RML, any R2RML available processor is able to deal with our approach. In our case, we integrate the RMLC-processor with Morph-RDB to query statistics data using SPARQL.
Evaluation
In this section we describe our experiment of transforming two statistics datasets from two different domains and agencies: a tourism statistics dataset from the Sri Lanka Tourism Development Authority (SLTDA) and a immigration statistics from the EuroStat. For each dataset, we use both R2RML and RMLC mappings with Morph-RDB to generate virtual SKGs and evaluate three SPARQL queries for each one. All the datasets, queries, results, code and mapping are available online.
Case 1: Statistics from the Sri lanka Tourism Development Authority
Dataset and Queries
The Sri Lanka Tourism Development Authority performs data collection and market research about tourism in Sri Lanka and publishes comprehensive statistics as PDF files. We use tabula-java to extract these statistics as CSV files and make them available online. For example, the CSV file that contains the number of passengers grouped by countries (y-axis) and the arrival months (x-axis) in 2016.
Our intention is to transform that CSV file into a virtual SKG. Because this SKG is not materialized, there is no need to store it in a dedicated triple store. Any R2RML engine with query translation support will be able to answer SPARQL queries posed to the dataset. For example, consider the following three queries:
Q1: Retrieve observations of the number of incoming tourist originated from Spain in 2016.
Q2: Retrieve observation of the number of incoming tourists in May 2016.
Q3: Can be seen as the combination between Q1 and Q2, i.e., retrieve observations of the number of incoming tourists from Spain in May 2016.
Mappings
The R2RML mapping document generated using the naive approach described in the previous section contains 12 TriplesMaps and around 700 lines. Each TriplesMap describes the transformation rules of the number of arriving passengers every month of the year. Except for those PredicateObjectMap properties corresponding to the name the CSV columns, all TripleMaps have identical values.
On the contrary, the corresponding RMLC mappings, either with rmlc:column property or with rmlc:range property have only 74 lines in total with 1 TriplesMap and 5 PredicateObject mappings. The summarizes the characteristics of the mappings.
R2RML
RMLC
Total lines
∼700
74
#TriplesMaps / #SubjectMaps
12
1
# PredicateObjectMaps
60
5
Comparison between R2RML and RMLC mappings used in the Srilanka Tourism dataset example.
Case 2: EuroStat - Immigration Statistics
Dataset and Queries
Eurostat the statistical office of the European Union. Its main responsibility is to provide statistical information about European Union such as economy, finance, population, industry, etc. In this example, we consider a dataset containing the number of immigrants that have arrived in European countries available online. We downloaded the aforementioned dataset as a CSV file containing the number of immigrants grouped by countries (x-asis) and years (y-axis). We have created three SPARQL queries, similar to the ones in the previous example:
Q1: Retrieve the number of immigrants arriving in Spain.
Q2: Retrieve the number of immigrants arriving in any of European Countries in the year of 2015.
Q3: Retrieve the number of immigrants arriving in Spain in the year of 2015.
Mappings
Generating the naive mapping described in the first approach is not feasible in this case, as there is a need to generate a TriplesMap for each column that represents a country and the dataset contains more than 40 columns. Instead, we generate two RMLC mapping documents,one with rmlc:columns property and the other with rmlc:range property. Then we use the RMLC Processor to generate the naive version of R2RML.
The RMLC mapping document (either version) contains only 1 TriplesMap and 4 PredicateObjectMap mappings, totalling less than 70 lines. On the contrary, the generated R2RML mapping document has more than 40 TriplesMap, more than 170 PredicateObjectMap mappings, totalling more than 2800 lines. The summarizes the characteristics of the mappings.
R2RML
RMLC
Total lines
>2800
<70
#TriplesMaps / #SubjectMaps
>40
1
# PredicateObjectMaps
>170
4
Comparison between R2RML and RMLC mappings used in the Eurostat Immigration dataset example.
Conclusion and Future Work
In this paper we have discussed and compared the approaches to generate virtual SKG from statistics datasets: using R2RML mappings and an extension of RMLC mappings including iterator variables. We apply those approaches to two real statistics datasets and showed that the approach using RMLC mapping drastically reduces the size of the R2RML mapping documents. Besides, as we provide a mechanism to transform the RMLC mapping to R2RML mappings, the performance of the virtualization process is not affected.
While it is now much easier to work with RMLC mappings, they still need to be generated manually using text editors that are not specifically designed to generate RMLC mappings. In the future we plan to develop a mapping editor for RMLC in order to facilitate ease generating of the mappings.
Acknowledgments
This research is supported by the MobileAge (H2020/693319), by Ministerio de Economía, Industria y Competitividad and EU FEDER funds under the DATOS 4.0: RETOS Y SOLUCIONES - UPM Spanish national project (TIN2016-78011-C4-4-R) and by the FPI grant (BES-2017-082511).
References
Oscar Corcho, Idafen Santana-Pérez, Hugo Lafuente, David Portolés, César Cano Alfredo Peris, José María Subero: "Publishing Linked Statistical Data: Aragón, a Case Study", Proceedings of the Joint Proceedings of the International Workshops on Hybrid Statistical Semantic Understanding and Emerging Semantics, and Semantic Statistics (HybridSemStats), 2017
Cyganiak, R., Reynolds, D., & Tennison, J. (2012). The RDF Data Cube Vocabulary, W3C Recommendation 16 January 2014. World Wide Web Consortium.
Priyatna, F., Corcho, O., & Sequeda, J. (2014, April). Formalisation and experiences of R2RML-based SPARQL to SQL query translation using morph. In Proceedings of the 23rd international conference on World wide web (pp. 479-490). ACM.
D. Calvanese, B. Cogrel, S. Komla-Ebri, R. Kontchakov, D. Lanti, M. Rezk, M. RodriguezMuro, and G. Xiao (2017). Ontop: Answering SPARQL queries over relational databases. Semantic Web, 8(3), 471-487.
Poggi, A., Lembo, D., Calvanese, D., De Giacomo, G., Lenzerini, M., & Rosati, R. (2008). Linking data to ontologies. In Journal on data semantics X (pp. 133-173). Springer, Berlin, Heidelberg.
RDF Mapping Language, W3C Recommendation 27 September 2012. Cambridge, MA: World Wide Web Consortium (W3C) (www.w3.org/TR/r2rml) (2012).
Artem Chebotko, Shiyong Lu, and Farshad Fotouhi. 2009. Semantics preserving SPARQL-to-SQL translation. Data & Knowledge Engineering 68, 10 (2009), 973–1000
Mariano Rodriguez-Muro and Martin Rezk. 2015. Efficient SPARQL-to-SQL with R2RML mappings. Web Semantics: Science, Services and Agents on the World Wide Web 33 (2015), 141–169
Areti Karamanou Evangelos Kalampokis Efthimios Tambouris Konstantinos Tarabanis, Publication of Statistical Linked Open Data in Japan, SemStats 2016 (ISWC)
Anastasia Dimou, Miel Vander Sande, Pieter Colpaert, Ruben Verborgh, Erik Mannens, and Rik Van de Walle. 2014. RML: A Generic Language for Integrated RDF Mappings of Heterogeneous Data.. In LDOW.
Franck Michel, Loıc Djimenou, Catherine Faron-Zucker, and Johan Montagnat. 2015. Translation of relational and non-relational databases into RDF with xR2RML. In 11th International Conference on Web Information Systems and Technologies (WEBIST’15). 443–454.
Andreas Langegger and Wolfram Woß. 2009. XLWrap–querying and integrating arbitrary spreadsheets with SPARQL. In International Semantic Web Conference. Springer, 359–374
Claus Stadler, Jorg Unbehauen, Patrick Westphal, Mohamed Ahmed Sherif, and Jens Lehmann. 2015. Simplified RDB2RDF Mapping. In LDOW@WWW
Hoekstra, R., Merono-Penuela, A., Dentler, K., Rijpma, A., Zijdeman, R., & Zandhuis, I. (2016, May). An ecosystem for linked humanities data. In International Semantic Web Conference (pp. 425-440). Springer, Cham.
Knoblock, C. A., Szekely, P., Ambite, J. L., Gupta, S., Goel, A., Muslea, M., Lerman, K., Taheriyan, M., and Mallick, P (2012, May). Semi-automatically mapping structured sources into the semantic web. In Extended Semantic Web Conference (pp. 375-390). Springer, Berlin, Heidelberg.
Tennison, J., Kellogg, G., and Herman, I. (2015). Model for tabular data and metadata on the web. W3C recommendation. World Wide Web Consortium (W3C).
* This work will be published as part of the book “Emerging Topics in Semantic Technologies. ISWC 2018 Satellite Events. E. Demidova, A.J. Zaveri, E. Simperl (Eds.), ISBN: 978-3-89838-736-1, 2018, AKA Verlag Berlin”.